SEO
MVOP WBF
Bc. Matěj Cajthaml — SSPŠ
©
SEO
SEO
- = Search Engine Optimalization
- způsob jak donutit vyhledávače označovat stránku jako relevantní
Co je to vyhledávač? Jaké znáte
Indexace
- proces, kdy je nějaká stránka připojena do vyhledávání
- nastává automaticky a nebo žádostí u vyhledávače
Jak může dojít k automatické indexaci?
Crawling
- indexer a crawler
- proces, kdy je stránka a všechny její odkazy procházeny
- neprobíhá na jedné stránce neustále, různé časy návratů
Po crawlingu
- stránka a její informace je uložena do indexu
- při vyhledávání se zkontroluje index
Co zadáváme při vyhledávání? Co je tedy v indexu?
Děláme optimalizaci pouze pro vyhledávače?
Sémantický web
Jedna z nejdůležitějších věcí pro SEO je samotná stránka.
Správné rozdělení webu
HTML— slouží pouze na určení obsahu a jejich propojeníCSS— slouží k nadesignování HTML
Takto to asi obyčejně neděláte, ne?
Sémantický web
- každý prvek má svůj význam a proto je použiván
- žádné bez-významové tagy, jako např.
divčispan - HTML5 rozložení
Sémantický web
Práce
Vytvořme si moderní sémantické rozdělení.
Proč je efektivní, sémantické a jak vyhledávač pozná věci?
Pozice
Co pozici ve vyhledávání určuje?
Může pozici ovlivňovat rychlost načtení stránky?
Závislost pozice
- vyhledávací text
- obsah stránky
- rychlost stránky v době crawlingu
- ostatní stránky
Pozice nelze však takto jednoduše počítat. Jde i o další údaje a nebo to není takto přímočaré.
Proč existují firmy, které se právě pouze SEO zaobírají?
Proč mají vyhledávače takové kontroly? O co vlastně vyhledávačům jde?
Povrchové zlepšení SEO
- popisovat obsah, např. pomocí
alt - používat různé slova
- dodržovat správnou hierarchickou strukturu stránek
- mít správný nadpis stránky a nadpisové tagy
- nastavit důležité tagy
metatag
Další zlepšení SEO
Práce
Nalezněte na internetu, jaké další postupy a úpravy doporučují různé stránky, zabívající se SEO.
Ovládání robota
Často se nám stává, že roboty k crawlingu a nebo vůbec indexaci nechceme pustit, proč?
robots.txt
- určuje jak se stránka bude crawlovat
- můžeme zamezit či různě upravovat
- různý syntax
- soubor je v kořenovém adresáři
Tvorba souboru
Přidání pravidla zablokování všech na určité URL zaručí, že na soubor nikdo nebude moci přistoupit, že?
Musí vyhledávače a jiní roboti tento soubor respektovat?
Zablokování crawlerů
- často se stává, že vyhledávač vynechá
robots.txtkvůli jiné stránce - můžeme přidat metatag, který vypne indexaci na této stránce
<meta name="robots" content="noindex">- nebo hlavička
X-Robots-Tag
Sitemapy
- speciální soubor, který určuje jaké stránky jsou pro danou stránku důležité
- format
XML - určujeme taktéž prioritu a preferovaný čas crawlingu
Tvorba souboru
Sitemapy stránek
Práce
Navštivte stránky ssps.cajthaml.eu, ssps.cz a nějakou dle vašeho
výběru. Porovnejte sitemapy.
Sitemapy pro TODO aplikace
Práce
Vytvořte sitemapu pro naši TODO aplikaci.
Problémy frameworků se SEO
Jak vypadá zdrojový kód zkompilované Vue aplikace?
Jak načítá vyhledávač stránku?
Načítání stránky vyhledávačem
- stránka v minulosti se nespouštěla — indexace byla spouštěna na HTML
- frameworky ale generují a reagují (pomocí AJAX) až při načtení v prohlížeči
- (minimálně) dvě řešení: SSR a prerender
- nyní se stránky spustí ve fiktivním prohlížeči až po nějaké době se začnou indexovat
Po jaké době se začnou indexovat? Co je ten fiktivní prohlížeč? Není to nebezpečné a náročné na HW?
Server-side Rendering
- způsob, kdy je aplikace vykreslena na serveru a poté je poslána na prohlížeč
- stránka tedy má při indexaci již vše připravené
- většinou musí podporovat framework a musí běžet služba na serveru
Jaké jsou další výhody SSR? Co nevýhody?
Díky SSR je možné na prohlížeč poslat data ze serveru bez nutnosti, aby věděl jak a kde se vzali.
Prerender
- zjedndoušené SSR, bez nutnosti a závilosti na frameworku
- jednotlivé požadavky pro roboty (ale i uživatele) předkreslí a poté cachuje
- problém se zaseknutou cache a obecně autorizací
Nekalé praktiky
Farma odkazů
- jednotlivé stránky si mohou své pozice upravovat pomocí odkazů
- vyhledávače se potýkají s problémem, kde stránky odkazují na různé stránky a tím zvedají jejich pozici
- proč je to špatné?
- jak to vyřešit?
- (více podrobně později)
Skrytý obsah
- uživatelovi se nevykreslí určitý text, který je v HTML
- proč je to špatné?
- jak to vyřešit?
Jiný obsah
- dle hlavičky
User-agentje zobrazován jiný obsah robotům a uživatelovi - proč je to špatné?
- jak to vyřešit?
Google Search Console
- dovoluje vidět to, co vyhledávač o Vaší stránce ví
- různé statistiky — průměrná pozice, vyhledávací termy, ...
- můžeme požádat o indexování
- je nutné ověřit vlastnění domény
Booleanový model
Booleanový model
- počítejme, že máme stránku s textem (tj. bez tagů)
- tento model nám dovoluje v takových textech hledat
- máme 2D tabulku, kde řádky jsou slova a sloupce jsou stránky, na kterých se nachází
- v každé buňce je 1, pokud je slovo na stránce, jinak 0
Ukázka tabulky
| Stránka 1 | Stránka 2 | Stránka 3 | Stránka 4 | |
|---|---|---|---|---|
| text | 1 | 1 | 1 | 1 |
| je | 1 | 1 | 1 | 0 |
| krásný | 1 | 0 | 0 | 0 |
| nejkrásnější | 0 | 1 | 0 | 0 |
| stránka | 0 | 0 | 1 | 1 |
Jednoduché hledání
- jednoduché dotazy:
nejkrásnější
- stačí se podívat na řádek s tímto slovem a vrátit hodnoty s 1
Ukázka jednoduchého dotazu
| Stránka 1 | Stránka 2 | Stránka 3 | Stránka 4 | |
|---|---|---|---|---|
| text | 1 | 1 | 1 | 1 |
| je | 1 | 1 | 1 | 0 |
| krásný | 1 | 0 | 0 | 0 |
| nejkrásnější | 0 | 1 | 0 | 0 |
| stránka | 0 | 0 | 1 | 1 |
Co budeme dělat, když chceme ale najít nejkrásnější stránku
?
Složitější dotazy
- např. dotaz:
nejkrásnější AND stránka
- postupně zpracováváme slova a výsledky spojujeme pomocí AND
- lze používat další operátory: AND, OR, NOT či další
Ukázka složitějšího dotazu
nejkrásnější OR stránka
| Stránka 1 | Stránka 2 | Stránka 3 | Stránka 4 | |
|---|---|---|---|---|
| text | 1 | 1 | 1 | 1 |
| je | 1 | 1 | 1 | 0 |
| krásný | 1 | 0 | 0 | 0 |
| nejkrásnější | 0 | 1 | 0 | 0 |
| stránka | 0 | 0 | 1 | 1 |
| VÝSLEDEK | 0 | 1 | 1 | 1 |
Jak vypadají výsledky dotazu?
Předzpracování dat
- před vytvořením tohoto indexu je nutné data předzpracovat
- např. odstranit interpunkci, číslice, převedení na malá písmena
- např. často se používá stemming (odstranění koncovky slova)
- např.
krásný
akrásnější
se spojí do jednoho slova - ... a další
- je nutné provést i na samotný dotaz
Jak tato tabulka — index, bude velký? Kolik bude mít řádků a sloupců?
Invertovaný seznam
- místo velké tabulky použijeme seznamy
- každé slovo bude mít seznam stránek, na kterých se vyskytuje
- seznam bude seřazený
- nad seřazeným seznamem se dělají akce velmi jednoduše
Ukázka invertovaného seznamu
| mám | 1 | 3 | |||
|---|---|---|---|---|---|
| rád | 1 | 2 | |||
| mvop | 1 | 2 | 3 | 4 | |
| je | 1 | 2 | 3 | 4 | |
| krásný | 3 | 4 | 12 | 15 | 203 |
Může nastat, že dotaz (mvop AND krásný) AND rád
bude rychlejší než mvop AND (krásný AND rád)
?
Je to, že stránka obsahuje nějaké slovo, dostatečným ukazatelem, že je stránka dotazu relevatní?
Takto ale asi na Googlu nehledáte, ne?
Výhody
- jednoduché pro uživatele
- přesné
Nevýhody
- velmi pomalé, mnoho zbytečného počítání
- nevhodné pro složité dotazy, dotazy nejsou jen binární operace
- ignoruje frekvenci slov, jejich relevanci a význam
- vrací neseřazený seznam
- ignorujeme sémantiku webu a jeho tagů
Toto vyhledávání se hodí právě tehdy, když víte co hledáte. Což skoro nikdy nevíte.
Rozšířený Booleanový model
Rozšířený Booleanový model
- řešení toho, že výsledek dotazu není seřazený a je příliš přesný
- jednotlivá slova místo toho, zda je stránka obsahuje, hodnotíme
- hodnocení je číslo od 0.00 do 1.00, např. podle frekvence
- výsledky jsou získány obyčejnými akcemi (> 0.0) a poté dle hodnocení seřazeny
Ukázka tabulky
| Stránka 1 | Stránka 2 | Stránka 3 | Stránka 4 | |
| mám | 0.43 | 0.00 | 0.45 | 0.0 |
|---|---|---|---|---|
| rád | 0.43 | 0.11 | 0.00 | 0.03 |
| mvop | 0.43 | 0.43 | 0.43 | 0.43 |
| je | 0.95 | 1.00 | 0.23 | 0.47 |
| krásný | 0.00 | 0.00 | 0.00 | 0.01 |
Jak počítáme hodnocení celého dotazu vůči jedné stránce?
Výhody
- jednoduché pro uživatele
- řadí výsledky dotazu
Nevýhody
- velmi, velmi časově náročné
- ignorujeme sémantiku webu a jeho tagů
Hodnocení slov na stránce
- automaticky
- přednost mají důležitá slova
- znovu předzpracování
- možnosti:
- hodnocení dle frekvence slov na stránce
- hodnocení dle frekvence slov na všech stránkách
- normalizace
Další modely
- vektorový model
- řeší problém nepřesného zadávání dotazu
- podobnosti, vektory
- latentní sémantické indexování
- význam spojení slov
- pravděpodobnostní model
- modely založené na strojovém učení
Hodnocení pozic
Hodnocení pozic
- = pagerank
- způsob jak zhodnotit, jak je stránka populární
Mapa stránek
- orientovaný graf
- node = stránky
- edge = propojení se šipkou
- odchozí odkaz
- příchozí odkaz
Co se získává jednodušeji? Seznam příchozích či odchozích odkazů?
Hodnocení
Nechť identifikátor stránky je Pi, její hodnocení Rk(P), číslo iterace k.
- všechny stránky ohodnotíme
1/n - provedeme několik iterací, pro každou stránku:
- za každou stránku
Pj, která směruje do přičteme: - hodnocení z minulé iterace / počtem odchozích odkazů
- seřadíme sestupně
Ukázka hodnocení
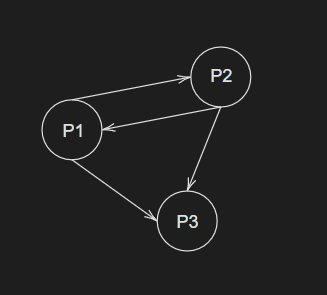
| Iterace 1 | Iterace 2 | Iterace 3 | Hodnocení |
|---|---|---|---|
| R1(P1) = 1/3 | R2(P1) = 1/6 | R3(P1) = 1/12 | 1 |
| R1(P2) = 1/3 | R2(P2) = 1/6 | R3(P2) = 1/12 | 1 |
| R1(P3) = 1/3 | R2(P3) = 1/3 | R3(P3) = 1/6 | 2 |
Kolikrát musíme iteraci provést?
Co když v grafu bude cyklus?
Vyhledávání
Vyhledávání
- uživatel zadá požadavek
- vyhledávač najde obsahově podobné stránky
- vyhledávač seřadí výsledky dle pageranku
Jsou při vyhledávání výsledky upravovány dle uživatele, který vyhledává? Kdy by takové seřazení nastalo?
Děkuji za pozornost!
- matej.cajthaml@ssps.cz
- https://ssps.cajthaml.eu/