Vyhledávání na webu a v multimédiích
DVOP4 PIT
Smíchovská střední průmyslová
škola a gymnázium
Vyhledávání na webu
Cíle
- máme velmi mnoho webových stránek
- webové stránky ukazují na jiné webové stránky
- stránky se ale často mění
- stránek je opravdu hodně
- rychlost vyhledávání
- přesnost vyhledávání
Multimédia
- obrázky
- videa
- zvuky
- dokumenty
- ...
- vizuální obsah, explicitní anotace, kontext
Obsah webových stránek
- moderní weby nejsou jen text
- různé tagy, struktura, ...
- v tom se nedá vyhledávat
- potřeba získat reprezentaci obsahu
Termíny
- dokument — obsahuje text (možná i anotace)
- kolekce — skupina dokumentů
- termín — slovo, které se v dokumentu vyskytuje
- slovník — všechny termíny z kolekce
Úprava před zpracováním
- odstranění interpunkce
- převod na malá písmena
- odstranění stop slov (předložky, spojky, číslovky, ...)
- zjednodušení slov: stemování, lemmatizace
- stemování: odstranění koncovky
- lemmatizace: převod na základní tvar (např. "běžet" -> "běh")
Klasifikace výsledků
- false positive
- false negative
- true positive
- true negative
Booleanův model vyhledávání
Booleanův model
- intuitivně je dokument seznamem termínů
- můžeme tedy reprezentovat jako vektor
- pro dotaz je termín = seznam dokumentů, ve kterých se vyskytuje
Vytvoření indexu
- matice/tabulka termínů a dokumentů
- pro každý termín zjistíme, ve kterých dokumentech se vyskytuje
- pokud je termín v dokumentu, je hodnota 1, jinak 0
- matice je řídká — většina hodnot je 0
Ukázka tabulky
| Stránka 1 | Stránka 2 | Stránka 3 | Stránka 4 | |
|---|---|---|---|---|
| text | 1 | 1 | 1 | 1 |
| je | 1 | 1 | 1 | 0 |
| krásný | 1 | 0 | 0 | 0 |
| nejkrásnější | 0 | 1 | 0 | 0 |
| stránka | 0 | 0 | 1 | 1 |
Dotaz
- dotaz je booleanový výraz
- např.
stránka AND krásný - výsledek je nějaká skupina dokumentů
- např. AND, OR, NOT ale i další
Invertovaný index
- pro každý termín máme seznam dokumentů, ve kterých se vyskytuje
- dané dokumenty jsou seřazeny dle svých identifikátorů
- velmi efektivní pro vyhledávání
Ukázka invertovaného indexu
| Termín | Dokumenty |
|---|---|
| text | 1, 2, 3, 4 |
| je | 1, 2, 3 |
| krásný | 1 |
| nejkrásnější | 2 |
| stránka | 3, 4 |
Může nastat, že dotaz (mvop AND krásný) AND rád
bude rychlejší než mvop AND (krásný AND
rád)
?
Výhody
- rychlé vyhledávání
- snadná implementace
Nevýhody
- takto nikdo dotazy nepíše
- neumožňuje porovnávání podobnosti
- ignoruje význam slov, slovní spojení, relevanci slov, ...
- vrací neseřazené výsledky
Rozšířený Booleanový model
Rozšířený Booleaný model
- řeší problém s neseřazenými výsledky
- přidává váhy termínům — místo 0 a 1 máme reálná čísla
- např. pomocí tzv. tf-idf
- $tf(t, d)$ = počet výskytů termínu $t$ v dokumentu $d$
- $idf(t, D)$ = $log\left(\frac{N}{|\{d \in D : t \in d\}|}\right)$
- $tf-idf(t, d, D) = tf(t, d) \cdot idf(t, D)$
Vyhodnocení dotazů
- složitější, mnoho cest
- např.:
- $= 0$ — je nula...
- $\gt 0$ — pocítáme jako s 1
- poté sečteme váhy termínů
- nebo lepší způsob...
Správné vyhodnocení
- dotaz: q =
a AND b - r(q, d) jako: $1 - \sqrt{\frac{(1 - w_{a,d})^2 + (1 - w_{b,d})^2}{2}}$
- dotaz: q =
a OR b - r(q, d) jako: $\sqrt{\frac{w_{a,d}^2 + w_{b,d}^2}{2}}$
Výhody
- řeší problém s neseřazenými výsledky
- umožňuje porovnávání podobnosti
- zohledňuje relevanci slov
Nevýhody
- komplikovanější implementace
- horší výkon
Vektorový model
Vektorový model
- často nevíme co hledáme
- chceme vidět i podobné výsledky
- dokumenty reprezentujeme jako vektory v prostoru termínů
- dotaz je také vektor
Jaká bude dimenze tohoto prostoru?
Záznam vektoru
- ve vektoru znouv máme váhy termínu
- znovu např. tf-idf, ale často již používáme i sémantické informace
- dotaz obdobně, ale stačí dát 1 pro takové termíny, které byly zadány v dotazu
- dotaz porovnáváme s vektory dokumentů
Porovnání
- euklidovská vzdálenost — $d(q, d) = \sqrt{\sum_{i=1}^{n}(q_i - d_i)^2}$
- kosinová podobnost — $d(q, d) = \frac{\sum_{i=1}^{n}q_i \cdot d_i}{\sqrt{(\sum_{i=1}^{n}q_i)^2 \cdot (\sum_{i=1}^{n}d_i)^2}}$
- zahrnuje i
směr
vektorů - určujeme rozmezí, kdy říkáme, že je dokument relevantní
- možnost invertovaného indexu
Výhody
- umožňuje porovnávání podobnosti
- dovoluje částečné shody
- zohledňuje relevanci slov
- vrací seřazené výsledky
Nevýhody
- jednoduché dotazy mohou vracet špatné výsledky
- problém s dimenzí
- neumí pracovat s závislostmi mezi slovy
Další modely
- latentní-semanticé modely (řeší problém s významem slov)
- pravděpodobnostní modely (např. Bayes)
- modely založené na strojovém učení
Analýza linků
Analýza linků
- důležitost stránky
- víme, že WWW je graf
- definujme:
- vnitřní link — odkaz z perspektivy stránky, na kterou se ukazuje
- vnější link — odkaz z perspektivy stránky, ze které se ukazuje
Vnitřní linky nejde v podstatě spočítat. Proč?
PageRank
- po dotazu seřadíme stránky podle důležitosti
- důležitost stránky je dána počtem a důležitostí stránek, které na ni odkazují, a jejich důležitostí, která se počítá podle toho, kdo na ně odkazuje, ...
- výpočet je iterativní, pravděpodobná stabilizace
Algortimus
- $r_k(P_i)$ hodnocení stránky $P_i$ v $k$-té iteraci
- $|P_j|$ počet stránek, které odkazují na $P_i$ (vnější linky)
- $B_{P_i}$ množina stránek, které odkazují na $P_i$
- $r_{k+1}(P_i) = \sum_{P_j \in B_{P_i}} \frac{r_k(P_j)}{|P_j|}$
Ukázka hodnocení
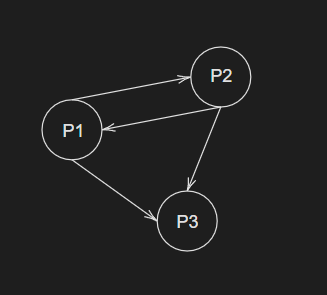
| Iterace 1 | Iterace 2 | Iterace 3 | Hodnocení |
|---|---|---|---|
| R1(P1) = 1/3 | R2(P1) = 1/6 | R3(P1) = 1/12 | 1 |
| R1(P2) = 1/3 | R2(P2) = 1/6 | R3(P2) = 1/12 | 1 |
| R1(P3) = 1/3 | R2(P3) = 1/3 | R3(P3) = 1/6 | 2 |
Jak dlouho bude trvat, než se stabilizuje PageRank?
HITS
Práce
Zjistěte, co je to HITS a jak funguje. Je lepší než PageRank?
SEO a nekalé praktiky
Práce
Co je to SEO? Jak SEO můžeme ovlivnit? Jaké nekalé praktiky znáte? Jak se proti nim brání vyhledávače?
Vyhledávání v multimédiích
Vyhledávání v multimédiích
- multimédia = obrázky, videa, zvuky, ...
- možné rozšíření na nestrukturovaný obsah
- můžeme vyhledávat na bázi textu (viz předchozí části)
- nutné anotace, nekompletní, lidská práce a chyby
Vyhledávání v multimédiích
- založeno na:
- extrakci příznaků — získání informací z multimédií, deskriptory
- podobnostní funkci — slouží k porovnávání příznaků
- při vyhledávání často využíváme dotaz ukázkou
Extrakce příznaků
- spousta privátních standardů a algoritmů
- detekce hran, barvy, tvary, ...
- často se používá histogra, Fourierova transformace, ...
- strojové učení
- nejznámější: SIFT, SURF, HOG, MPEG-7, ...
Podobnostní funkce
- mnoho možností
- vzdálenost Minkowského
- kosinová podobnost, kvadratická forma
- signature quadratic form distance
- earth mover's distance
- Hausdorff distance
- edit distance
- Levenshtein distance
- dynamic time warping distance
Ukázkový projekt
Práce
Vytvoříme aplikaci, která bude vyhledávat v sadě obrázků ty nejpodobnější k zadanému obrázku.
Děkuji za pozornost!
- matej.cajthaml@ssps.cz
- https://ssps.cajthaml.eu/